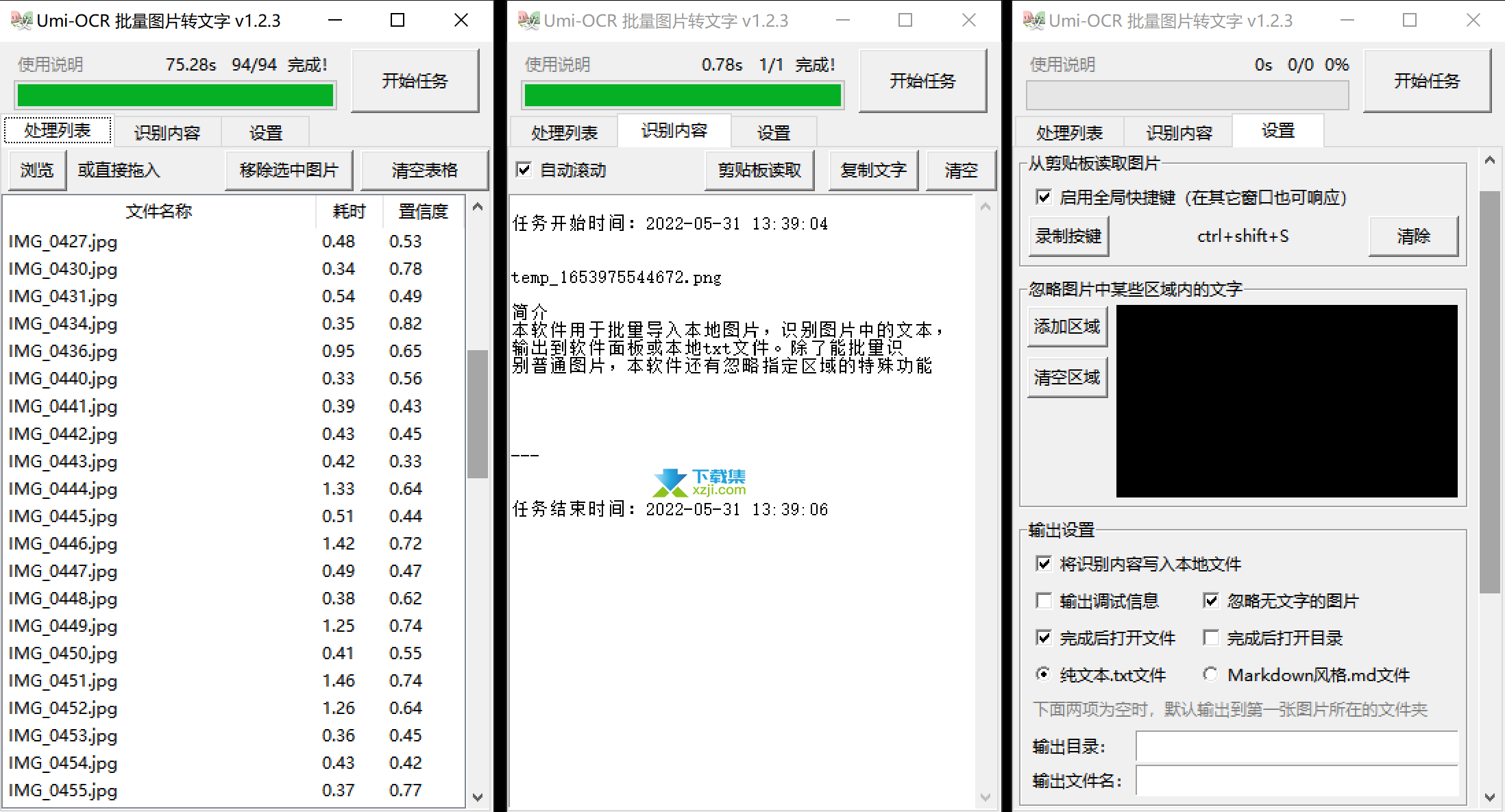
Umi-OCR批量图片转文字工具是一款离线OCR软件,批量导入本地图片 / 读取剪贴板,识别图片中的文本,输出到软件面板或本地 .txt / .md 文件。
免费:本项目所有代码开源,完全免费。
方便:解压即用,无需安装。不需要网络。
高效:OCR识别引擎是C++编译的PaddleOCR-json(PP-OCRv2.6 cpu_avx_mkl),比前代提速20%。只要电脑性能足够且支持mkldnn,通常能比在线OCR服务更快。
精准:默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对非常规字形(手写、艺术字、小字、方向不正、杂乱背景等)也有不错的识别率。可设置忽略区域排除水印,进一步提高精准性。
兼容性
系统支持 Win10 x64 。
不建议使用 Win7 ,识别引擎很可能无法运行。如果想尝试,win7 x64 sp1 打满系统升级补丁+安装vc运行库后有小概率能跑起来。
CPU必须具有AVX指令集。常见的家用CPU一般都满足该条件。
| AVX | 支持的产品系列 | 不支持 | 存疑 |
|---|
| Intel | 酷睿Core,至强Xeon | 凌动Atom,安腾Itanium | 赛扬CEleron,奔腾Pentium |
| AMD | 推土机架构及之后的产品,如锐龙Ryzen、速龙Athlon、FX 等 | K10架构及之前的产品 |
简单上手
准备
下载压缩包并解压全部文件即可。
批量识别本地图片文件
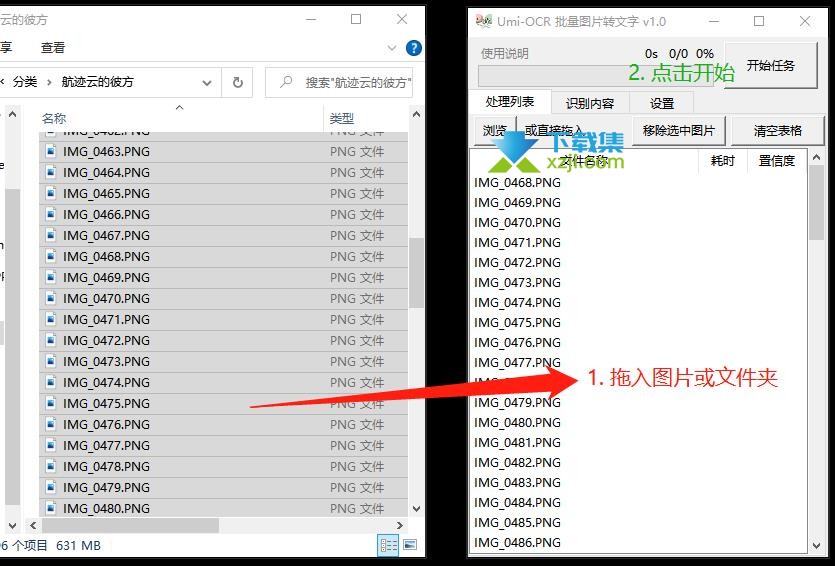
打开主程序,将任意图片/文件夹拖入窗口中的白色背景表格区域,或点击左上方的浏览选择图片。
点击右上方开始任务,等待进度条走完。
点击识别内容选项卡查看输出文字,或者前往第一张图片的目录查看识别结果txt文件。
快速识别剪贴板截图
按 [Win+Shift+S] 截取一张系统截图,或者在网页等地方复制一张图片。
切换到识别内容选项卡,点击剪贴板读取。
可以在设置选项卡中录制并启用全局快捷键,快速唤起程序识别。若此时程序窗口处在被覆盖的后方或者被最小化,则会自动挪到最前的位置。
设置说明
点击设置选项卡,配置参数。大部分设置项修改后会自动保存。
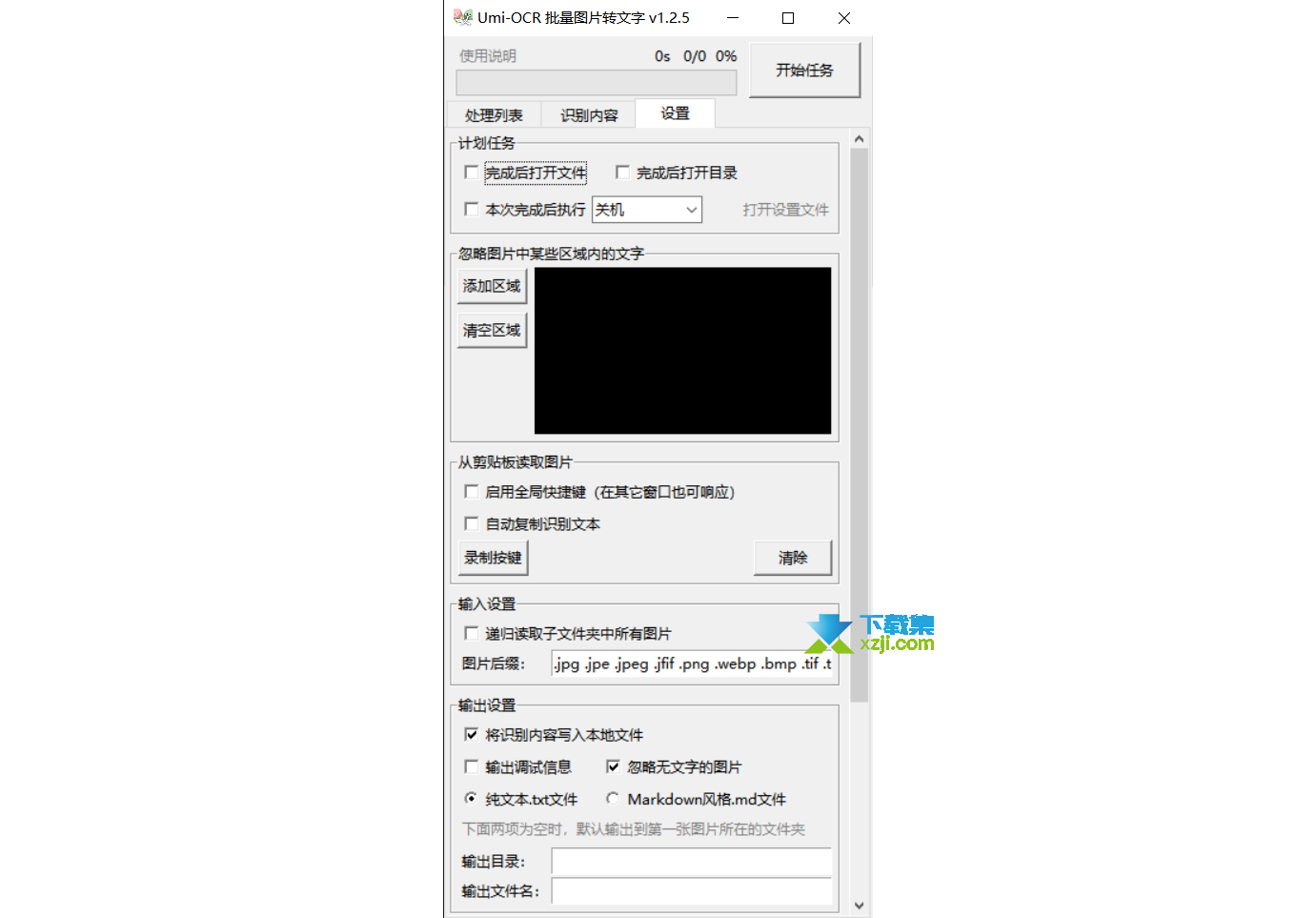
计划任务:
识图任务完成后,额外执行的任务。可执行打开生成文件/目录,自动关机/待机等。
即使识图任务正在进行中,也可以随意修改这些选项。
自定义计划任务
您可创建自己的计划任务,本质是调用一段cmd命令。
点击打开设置文件,在okMission中添加一项元素。
键为任务名称,值为字典,其中code为cmd命令。多条命令可用&分隔。例:
"我的任务": {"code": "cmd命令1 & 命令2"}
忽略图片中某些区域内的文字:
点击添加区域展开配置忽略区的新窗口。具体配置方式见后。
点击清空区域清空已配置的所有忽略区域参数。
已添加区域后,上方标题文字提示当前忽略区域的生效分辨率。
从剪贴板读取图片:
点击录制按键后按下想要的快捷键,如ctrl+shift+s。然后勾选启用全局快捷键。
按下快捷键后,程序检查当前剪贴板的第一位是否为图片,是则程序跳到顶层并展示识别文字。
请检查并避免全局快捷键与其它程序冲突。
可设置识图后自动复制识别内容(不含任务时间等信息的纯内容文本)。此设置只对剪贴板识图生效,批量任务时无效。
重要提示:v1.2.6版本提高了批量处理的平均速度,但代价是需要花费更长时间进行初始化。这可能影响剪贴板识图的速度(每次剪贴板任务都要重新初始化)。若频繁使用此功能,建议先使用旧版v1.2.5。
输入设置:
递归读取子文件夹中所有图片若勾选,拖入文件夹到处理列表时,会导入所有子文件夹中的图片。否则只会导入一层文件夹下的图片。
图片后缀正常情况无需改动。
图片后缀配置软件允许载入的图片后缀,不同后缀以空格分隔,必须全为小写。
如果你有必要添加新的图片后缀,要保证该图片同时满足c++模块的PaddleOCR和Python的PIL均可识别。比如.gif图片,虽然PIL可以识别,但PaddleOCR无法识别,载入gif文件会导致软件任务失败,因此不允许载入.gif。
不在许可后缀范围内的文件,拖入软件也不会被载入。目前默认的图片后缀为:.jpg .jpe .jpeg .jfif .png .webp .bmp .tif .tiff
输出设置:
将识别内容写入本地文件取消勾选后,不会再生成本地文件,只能在识别内容选项卡中查看输出信息。若设置了本次任务完成后自动关机,请务必勾选此项,以免至今为止的努力全部木大。
其他项正常情况无需改动。
输出调试信息若勾选,则会额外输出程序工作状态的内容。
忽略无文字的图片若勾选,则不含文字(或文字全被忽略区域屏蔽掉)的图片名称不会出现在输出信息中。
若想生成一份用于浏览的Markdown文件,则建议取消勾选。
生成文件可选择两种风格:纯文本.txt文件和Markdown风格.md文件。前者可用于查找等一般用途。后者在编辑器或浏览器中渲染为图文并茂的页面,可用于浏览和欣赏图集。
输出目录和输出文件名设置生成的文件的位置和名称。
当拖入第一张图片且这两项设置为空时,自动设置输出路径为第一张图片的父目录,输出文件名为[转文字]_{父目录}.txt。除非要自定目录和名称,否则这两项默认留空即可。
处理列表标签页的清空表格按钮,除了会清空已导入的图片列表,还会清空输出目录和输出文件名设置。这样下次拖入新图片时,就能在新的位置存放输出文件。
识别器设置:
识别语言选择当前识别语言(即OCR参数文件)。英文无需切换,所有语言均支持英文字母识别。
启动参数可输入字符串配置参数,调整识别过程,适应任务需求。